El Antipatrón de la Red Veloz
El Antipatrón de la Red Veloz
Hace un tiempo leí el excelente libro Fundamentals of Software Architecture (2020). Y me llamó la atención lo que los autores llaman falacia de la latencia cero.
Fui escéptico... ¿cómo podría saltarme algo tan obvio?
Mirando a las hojas del árbol
Uno de nuestros clientes pidió la modernización de sus aplicaciones web.
La razón: durante escenarios de alta demanda los servidores se caen.
La nube y su alta escalabilidad es una solución válida para este caso. Es así que comenzamos una PoC desplegando uno de los componentes en la nube.
Y reventamos de solicitudes a la PoC para probar la escalabilidad y resiliencia de nuestra arquitectura.
 resultados de las pruebas con locust
resultados de las pruebas con locust
Funcionaba con una mejora del 65% en tiempos de respuesta. Mucho mejor de lo que esperaba para la migración de un solo componente.
 ahora pienso que estábamos mirando las hojas del árbol en lugar del bosque
ahora pienso que estábamos mirando las hojas del árbol en lugar del bosque
¡Con esto íbamos a solucionar la demanda actual y además nos preparamos para el crecimiento esperado del negocio!
Acercando la lupa
Al principio prioricé las pruebas de estrés bajo alta demanda. Luego se me ocurrió que si hubo mejora en los escenarios extremos pues entonces la mejora también fue absoluta. El hardware de nuestras instancias en la nube era mejor, de todos modos. Así tenemos otro argumento para agregar las bullets de nuestra presentación.
Y ahí me reventó en la cara.
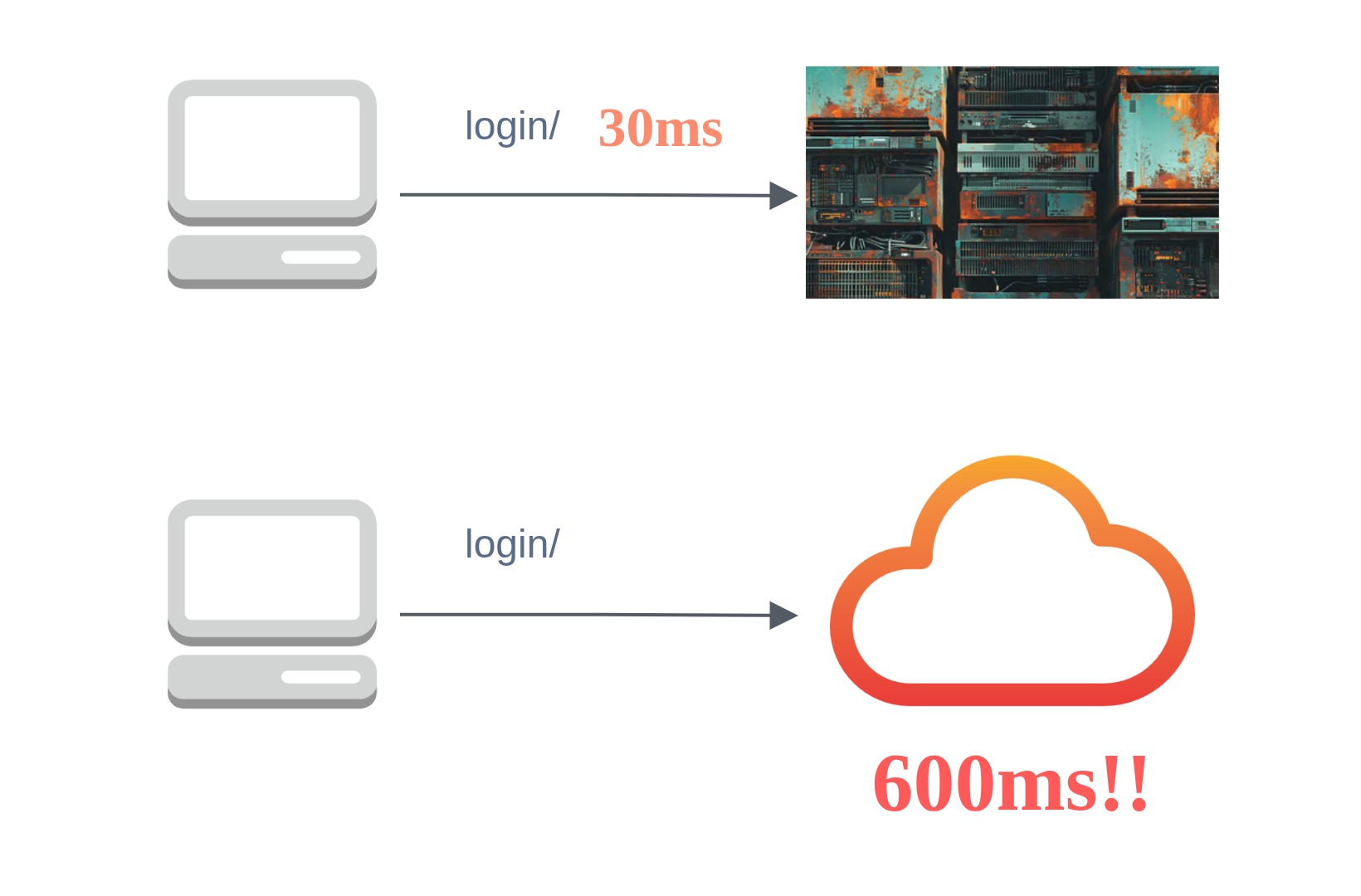
30ms on premises vs 600ms on cloud en uno de los endpoints. Y situación similar en los demás.
Ups...
No podía salirse de mi control una PoC ya casi cerrada. Me puse a investigar la causa raíz y recordé que nuestro componente en la nube, en EEUU, llama servicios aquí en Lima. A pesar de que todo se hace a través de Direct Connect, igual la latencia física es real.
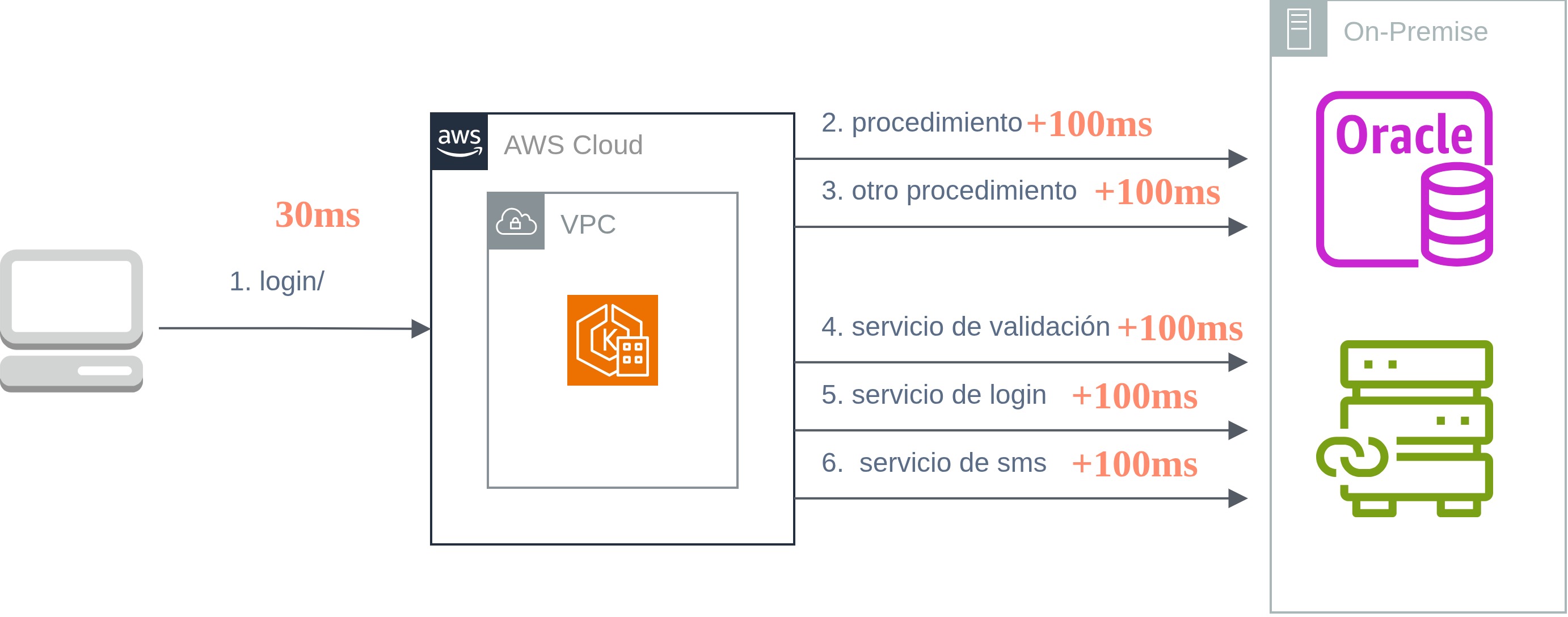 mi educación no es en teleco, pero aún me da risa pensar que no lo pensé antes
mi educación no es en teleco, pero aún me da risa pensar que no lo pensé antes
¿Y luego?
Conversamos con el cliente que si bien 600ms no es para morirse, en el percentil 95% se llega a valores de hasta 2 segundos. Y nadie aguanta eso en un login sin desesperarse. Menos en otros endpoints core.
Cambiamos el plan de despliegue de región a Brasil. Aquí tenemos mejor latencia.
Y estamos en evaluación sobre las siguientes etapas de la modernización. Hay que definir el despliegue progresivo de los nuevos microservicios de modo que la latencia no se convierta en un problema.
Nos gustaría migrar todos los componentes de un tiro, pero nuestro cliente pierde dinero al momento al que hablamos por culpa de la falta de escalabilidad.
Los microservicios y la nube tienen un costo oculto de latencia. Y otros más que se explican en el libro... que ahora tengo que repasar. 😅
Referencias
Mark Richard & Neal Ford. 2020. Fundamentals of Software Architecture: An Engineering Approach. O'Reilly